
Introduction
I will do my best to describe my system here, whithout to repeat my whole (not yet ready) thesis paper here. If your questions are not answered, then do not hesitate to contact me.
Generally I would use the following keywords to describe my work : adaptive interface toolkit, multimodal interfaces, XML interface description
Overview
I start here with a short list of the main characteristics of the GITK approach:
- it defines an adaptation infrastructure, which then drives adaptation methods. the focus of the project lies on developing the infrastructure, not the single methods
- heavily XML based (uses XML not just as an input format)
- lightweigth (it is C, it has only a few strict dependencies)
- it is open source
Components
 Like most other approches GITK uses a modular, multilayered architecture, but heavily
relies on XML processing through all the layers.
The architecture implements the ARCH model (which is an extension of the Seeheim model).
Lets briefly introduce the layers from top to bottom:
Like most other approches GITK uses a modular, multilayered architecture, but heavily
relies on XML processing through all the layers.
The architecture implements the ARCH model (which is an extension of the Seeheim model).
Lets briefly introduce the layers from top to bottom:
- application: the application itself is unaware of how the final interface will look and feel, it just delivers the functional dialog description and the event handling
- wrapper: these components allow the application developer to "freely" choose the prevered language for development
- core: this component is the only one the application talks to and forms the basic infrastructure, it further manages everything else (plugins, transformation pipeline, etc.)
- transformer plugins: these modules provide media neutral transformation (independend of the target domain), e.g. i18n
- renderer plugins: these are interpreters which generate and run the final interface. These modules encapsulate the complexity of a target domain. This includes all the domain knowledge needes for adaption methods in that domain.
 Now lets have a look at the architecture by it components. The images on the right shows that GITK:
Now lets have a look at the architecture by it components. The images on the right shows that GITK:- can support multiple programming languages
- can operate the interface on different targets (media)
- uses a flexible transformation pipeline
- adaptation methods (transformations) are separated from the infrastructure
- switch renderers at runtime: this is neccesary when you activly doing something else and use the application as a helper, the app can use e.g. speech I/O to communicate with you, then you might need to activly use the application to get more detail information, therefore speech I/O might not be sufficient and/or efficient enough.
- run multiple renderers at once: you are doing some work in a team, where each team member might need a different interface; you want to have a scripting interface runing parallel to the graphical interface to use macros.
Processing
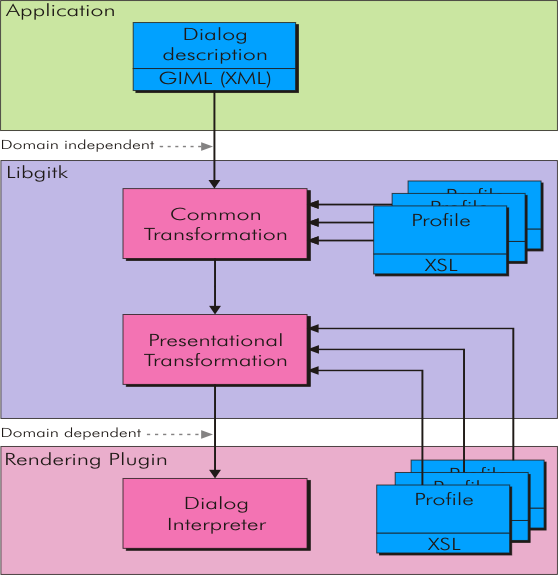 The image on the right gives a rought idea, how a XML dialog description (GIML) runs though all the
transformations steps and which components are involved in processing it.
The image on the right gives a rought idea, how a XML dialog description (GIML) runs though all the
transformations steps and which components are involved in processing it.
Most processing steps in the pipeline are already XSLT steps. They just apply a given XSL stylesheet
to the dialog description. The i18n processing step is a bit special. It adds a custom XSLT command to the style-sheet processor
(GITK uses GNU gettext catalogs and
I do not want to create a dependency on gettext to dynamicaly create a XSL stylesheet from
a catalog at runtime). In my opinion - the biggest advantage of the pipeline approach is, that it invites to
experiment, as the whole transformation process can easily be adapted and reconfigured.
The images show that the XML dialog description is provides by the application. Further one can see, that
additional information comes from "profiles" in the form of XSL stylesheets. These are provided
by the core system and the rendering modules.
GIML - the XML dialog descriptions
Like many other approaches, GITK uses a XML based markup language to describe dialogs. As a main difference
GIML avoids terms related to graphical presentation of dialogs, as such dialogs may be presented on any
media from audio to graphics.
Other XML interface languages use terms as "push-button", "scrollbar", whereas GIML uses terms
as "action", "data-entry/value-choice/single/limited". The goal is to use interface patterns in the
future. These media neutral identifiers are the foundation for an interface object hierarchy.
